Last week I discovered that there are bats behind my appartment. I immediately grabbed my “bat detector”: a device that converts the ultrasound signals bats use to echolocate from an inaudible frequency range to an audible one. The name “bat detector” thus is a lie: you can use it to detect bats, but it does not detect bats itself. In this tutorial I will show you how to build a real bat detector using Tensorflow.


Problem statement
To approach this problem I hooked up the bat detector to my laptop and recorded several clips. In a seperate Jupyter notebook I created a labeling program. This program creates “soundbites” of one second, which I classified as either containing the sound of a bat, or not containing the sound of a bat. I take the data and labels to create a classifier that can distinguish them.
Libraries to recognize sound
There are some very useful libraries I imported to be able to build a sound recognition pipeline. Obvious libraries I imported are Tensorflow, Keras, and scikit. A sound-specific library I like is librosa, which helps me load and analyze the data.
import random
import sys
import glob
import os
import time
import IPython
import matplotlib.pyplot as plt
from matplotlib.pyplot import specgram
import librosa
import librosa.display
from sklearn.preprocessing import normalize
import numpy as np
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Dropout, Flatten
Loading sound data with Python
In the data labeling notebook we typed in labels, and saved soundbytes to the folder we typed in. By loading from these folders I can load bat sounds and non-batsound files. Depending on how many soundfiles there are loading this data can take a long time. I uploaded all files in a zipped folder to the Google Cloud Platform.
- [Labeled sounds](https://storage.googleapis.com/pinchofintelligencebucket/labeled.zip)
- [Raw sounds](https://storage.googleapis.com/pinchofintelligencebucket/batsounds.zip)
Note that this notebook itself can also be downloaded from its Git repository. Apparently sounds in a Jupyter notebook are scaled and way louder than in wordpress/medium. You might have to turn your sound up a lot!
# Note: SR stands for sampling rate, the rate at which my audio files were recorded and saved.
SR = 22050 # All audio files are saved like this
def load_sounds_in_folder(foldername):
""" Loads all sounds in a folder"""
sounds = []
for filename in os.listdir(foldername):
X, sr = librosa.load(os.path.join(foldername,filename))
assert sr == SR
sounds.append(X)
return sounds
## Sounds in which you can hear a bat are in the folder called "1". Others are in a folder called "0".
batsounds = load_sounds_in_folder('labeled/1')
noisesounds = load_sounds_in_folder('labeled/0')
print("With bat: %d without: %d total: %d " % (len(batsounds), len(noisesounds), len(batsounds)+len(noisesounds)))
print("Example of a sound with a bat:")
IPython.display.display(IPython.display.Audio(random.choice(batsounds), rate=SR,autoplay=True))
print("Example of a sound without a bat:")
IPython.display.display(IPython.display.Audio(random.choice(noisesounds), rate=SR,autoplay=True))
Visualizing sounds with Librosa
When listening to the bats with your headphones you can hear a clear noise when one flies by. The Librosa library can perform a Fourier transform to extract the frequencies the sound is composed of.
Before building any machine learning algorithm it is very important to carefully inspect the data you are dealing with. In this case I decided to:
- listen to the sounds
- plot the soundwave
- plot the spectogram (a visual representation of the amplitude of frequencies through time).
def get_short_time_fourier_transform(soundwave):
return librosa.stft(soundwave, n_fft=256)
def short_time_fourier_transform_amplitude_to_db(stft):
return librosa.amplitude_to_db(stft)
def soundwave_to_np_spectogram(soundwave):
step1 = get_short_time_fourier_transform(soundwave)
step2 = short_time_fourier_transform_amplitude_to_db(step1)
step3 = step2/100
return step3
def inspect_data(sound):
plt.figure()
plt.plot(sound)
IPython.display.display(IPython.display.Audio(sound, rate=SR))
a = get_short_time_fourier_transform(sound)
Xdb = short_time_fourier_transform_amplitude_to_db(a)
plt.figure()
plt.imshow(Xdb)
plt.show()
print("Length per sample: %d, shape of spectogram: %s, max: %f min: %f" % (len(sound), str(Xdb.shape), Xdb.max(), Xdb.min()))
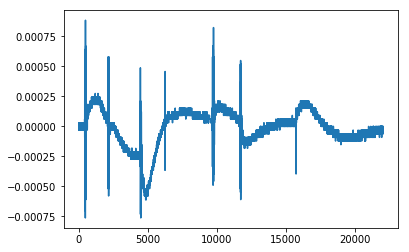
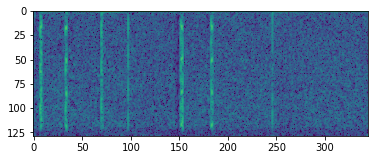
inspect_data(batsounds[0])
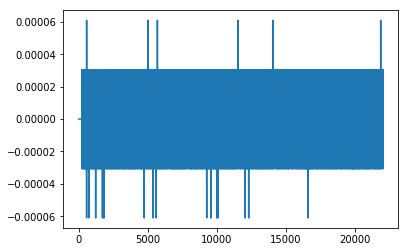
inspect_data(noisesounds[0])

Data analysis
First of all it’s important to note that the data we are dealing with is not exactly big data… With only around 100 positive samples, deep neural networks are very likely to overfit on this daa. A problem we are dealing with is that it is easy to gather negative samples (just record a whole day without bats) and difficult to gather positive samples (bats are only here for about 15-20 minutes a day, and I need to manually label data). The low amount of positive samples is something we take into consideration when determining how we are going to classify the data.
Audio signal
As we can see above the amplitude of the signal is low with the noise, while the signal has high amplitudes. However, this does not mean that everything with a sound in it is a bat. At this frequency you also pick up other noises, such as rubbing your fingers together or telephone signals.
I decided to put every negative signal onto one big “negative” pile, combining telephone signals, finger-induced noise, and other stuff in one big pile.
Spectrogram
I was hoping the see the exact frequency bats produce back in our spectogram. Unfortunately it looks like my sensor picks it up as noise over ALL frequencies. Looking at the spectrogram you can still see a clear difference between bat-sound and noise. My first attempt was to use this spectrogram as input for a convolutional neural network. Unfortunately, using only a few positive samples, it was very difficult to train this network. I thus gave up on this approach.
In the end I decided to go with a “metadata approach”. I divide every second of sound in 22 parts. For each part I determine the max, min, mean, standard deviation, and max-min of the sample. The reason I take this approach is because the “bat signals” DO clearly show up as a not of high-amplitude signals in the audio visualisation. By analyzing different parts of the audio signal, I can find out if multiple parts of the signal have certain features (such as a high standard deviation), and thus detect a bat call.
WINDOW_WIDTH = 10
AUDIO_WINDOW_WIDTH = 1000 # With sampling rate of 22050 we get 22 samples for our second of audio
def audio_to_metadata(audio):
""" Takes windows of audio data, per window it takes the max value, min value, mean and stdev values"""
features = []
for start in range(0,len(audio)-AUDIO_WINDOW_WIDTH,AUDIO_WINDOW_WIDTH):
subpart = audio[start:start+AUDIO_WINDOW_WIDTH]
maxval = max(subpart)
minval = min(subpart)
mean = np.mean(subpart)
stdev = np.std(subpart)
features.extend([maxval,minval,mean,stdev,maxval-minval])
return features
metadata = audio_to_metadata(batsounds[0])
print(metadata)
print(len(metadata))
Data management
As with every machine learning project it’s important to make an input-output pipeline. We defined functions to get “metadata” from our sound files: we can make audio spectograms, and simply take multiple samples of meta-features in the audio data. The next step is to map our preprocessing function to our training and test data. I first apply a preprocessing step to each audio sample, and keep the bat and nonbat sounds in two different lists. Later I join the sounds and labels.
In this case we are dealing with few “positive” samples, and a lot of negative samples. In such a case it’s a really good idea to normalise all your data. My positive samples will probably differ from the normal distribution, and will be easy to detect. To do this I use the scikit learn sklearn.preprocessing function “normalize”. During training I found out that my idea of standardization and normalization are exactly opposite of the scikit definitions. In this case this probably won’t be a problem, as normalizing a bat sound probably still yields a different result than normalizing a noise sound.
# Meta-feature based batsounds and their labels
preprocessed_batsounds = list()
preprocessed_noisesounds = list()
for sound in batsounds:
expandedsound = audio_to_metadata(sound)
preprocessed_batsounds.append(expandedsound)
for sound in noisesounds:
expandedsound = audio_to_metadata(sound)
preprocessed_noisesounds.append(expandedsound)
labels = [0]*len(preprocessed_noisesounds) + [1]*len(preprocessed_batsounds)
assert len(labels) == len(preprocessed_noisesounds) + len(preprocessed_batsounds)
allsounds = preprocessed_noisesounds + preprocessed_batsounds
allsounds_normalized = normalize(np.array(allsounds),axis=1)
one_hot_labels = keras.utils.to_categorical(labels)
print(allsounds_normalized.shape)
print("Total noise: %d total bat: %d total: %d" % (len(allsounds_normalized), len(preprocessed_batsounds), len(allsounds)))
## Now zip the sounds and labels, shuffle them, and split into a train and testdataset
zipped_data = zip(allsounds_normalized, one_hot_labels)
np.random.shuffle(zipped_data)
random_zipped_data = zipped_data
VALIDATION_PERCENT = 0.8 # use X percent for training, the rest for validation
traindata = random_zipped_data[0:int(VALIDATION_PERCENT*len(random_zipped_data))]
valdata = random_zipped_data[int(VALIDATION_PERCENT*len(random_zipped_data))::]
indata = [x[0] for x in traindata]
outdata = [x[1] for x in traindata]
valin = [x[0] for x in valdata]
valout = [x[1] for x in valdata]
Machine learning model
To detect the bats I decided to try a very simple neural network with three hidden layers. With too little trainable parameters the network can only make a distinction between no-sound and sound. With too many trainable parameters the network will easily overfit on the small dataset we have.
I decided to implement this network in Keras, this libary gives me the best functions to easily try different neural network architectures on this simple problem.
LEN_SOUND = len(preprocessed_batsounds[0])
NUM_CLASSES = 2 # Bat or no bat
model = Sequential()
model.add(Dense(128, activation='relu',input_shape=(LEN_SOUND,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(2))
model.compile(loss="mean_squared_error", optimizer='adam', metrics=['mae','accuracy'])
model.summary()
model.fit(np.array(indata), np.array(outdata), batch_size=64, epochs=10,verbose=2, shuffle=True)
valresults = model.evaluate(np.array(valin), np.array(valout), verbose=0)
res_and_name = zip(valresults, model.metrics_names)
for result,name in res_and_name:
print("Validation " + name + ": " + str(result))
Results and implementation of detection pipeline
With an accuracy of 95 percent on the validation set it looks like we are doing really well. The next step is checking if we can any bats in a longer piece of audio we never processed before. I took a recording I made after the bats were pretty much gone, let’s see if we can find any:
soundarray, sr = librosa.load("batsounds/bats9.m4a")
maxseconds = int(len(soundarray)/sr)
for second in range(maxseconds-1):
audiosample = np.array(soundarray[second*sr:(second+1)*sr])
metadata = audio_to_metadata(audiosample)
testinput = normalize(np.array([metadata]),axis=1)
prediction = model.predict(testinput)
if np.argmax(prediction) ==1:
IPython.display.display(IPython.display.Audio(audiosample, rate=sr,autoplay=True))
time.sleep(2)
print("Detected a bat at " + str(second) + " out of " + str(maxseconds) + " seconds")
print(prediction)
Conclusion, and similar projects
In the end my sensor detected 1 bat at a time when there was probably no bat outside (but I can’t verify this) in 26 minutes of audio. I will conclude that my program works! Now we are able to integrate this program in a small pipeline to warn me whenever there is a bat outside, or we can make a recording every day and measure the bat activity day to day.
While working on this project the Nature Smart Cities project created the Bats London project. Per sensor you can see the bat activity. Also interesting is that their sensor is able to capture way more interesting sounds, such as this social call made by a bat. It is great to see others are also interested in this subject, and it’s great to compare approaches. The bats London project built nice boxes with a computer in it that does all processing based on a spectogram. They use convolutional neural networks based on 3-second sound files they record every 6 seconds. In the future they even want to start to make a distinction between different species of bats! They did a great job with a very interesting project!

I spent my early electronic youth fascinated by bats. I thought it would be neat to be able to ‘hear’ bats in real time by moving their bursts down to an audible frequency band. I still do. I wonder if other animal sounds could be ‘heard’ in that way also. Maybe electric field of fish for example.
There are several ways to make batsounds audible. The simpliest way electronically is heterodyning
the second easiest way is frequency division. Note batspecies use different frequency ranging from 220 kHz till 12 kHz. So Scanning shifting or panorama heterodyning is nesecarry.
But if you have your signal digitally time expansion (10x) (pitch conversion) is the easiest way. Just alter the headerfile sound format info en presto you can play sounds 10x slower.
But since the later is not realtime and rythm is also important to recognize species you could compress call intervals to real time again. Many bats have a call duty cycle of <10%.
Thanks for sharing. I have just started to look into machine learning and decided some weeks ago to have a deeper look at Tensorflow and librosa. Perfect timing. My current solution is to start recording when something happens above 15 kHz and manual analysis using the free software Sonic Visualiser. I will try to use ML to group different sounds and t-SNE may be a candidate to start with. Bat species identification will still be hard even with ML since the echolocation sounds are functional sounds and a lot of species can produce the same kind of sound depending on what they are doing and the surroundings.
My project is about developing free and open software for bat workers and scientist and the GitHub repository can be found here: cloudedbats.org
Hi,
I need help about the last step, I have an error and I could not resolve this by myself.
Do you have any idea for this error ? (I use a sound of 4sec during the “librosa.load(mysound)”)
At this line : prediction = model.predict(testinput)
ValueError: Error when checking : expected dense_1_input to have shape (440,) but got array with shape (110,)
Hi,
Thanks for sharing.,I am very interesting in your Detecting bats,how to obtain the sound data?