The OpenAI gym environment is one of the most fun ways to learn more about machine learning. Especially reinforcement learning and neural networks can be applied perfectly to the benchmark and Atari games collection that is included. Every environment has multiple featured solutions, and often you can find a writeup on how to achieve the same score. By looking at others approaches and ideas you can improve yourself quickly in a fun way.I noticed that getting started with Gym can be a bit difficult. Although there are many tutorials for algorithms online, the first step is understanding the programming environment in which you are working. To easy new people into this environment I decided to make a small tutorial with a docker container and a jupyter notebook.
What you need
Before you get started, install Docker. Docker is a tool that lets you run virtual machines on your computer. I created an “image” that contains several things you want to have: tensorflow, the gym environment, numpy, opencv, and some other useful tools.
After you installed Docker, run the following command to download my prepared docker image:
docker run -p 8888:8888 rmeertens/tensorflowgymIn your browser, navigate to: localhost:8888 and open the OpenAI Universe notebook in the TRADR folder.
Play a game yourself
Let’s start by playing the cartpole game ourselves. You control a bar that has a pole on it. The goal of the “game” is to keep the bar upright as long as possible. There are two actions you can perform in this game: give a force to the left, or give a force to the right. To play this game manually, execute the first part of the code.
By clicking left and right you apply a force, and you see the new state. Note that I programmed the game to automatically reset when you “lost” the game.
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import widgets
from IPython.display import display
import gym
from matplotlib import animation
from JSAnimation.IPython_display import display_animation
def leftclicked(something):
""" Apply a force to the left of the cart"""
onclick(0)
def rightclicked(something):
""" Apply a force to the right of the cart"""
onclick(1)
def display_buttons():
""" Display the buttons you can use to apply a force to the cart """
left = widgets.Button(description="<")
right = widgets.Button(description=">")
display(left, right)
left.on_click(leftclicked)
right.on_click(rightclicked)
# Create the environment and display the initial state
env = gym.make('CartPole-v0')
observation = env.reset()
firstframe = env.render(mode = 'rgb_array')
fig,ax = plt.subplots()
im = ax.imshow(firstframe)
# Show the buttons to control the cart
display_buttons()
# Function that defines what happens when you click one of the buttons
frames = []
def onclick(action):
global frames
observation, reward, done, info = env.step(action)
frame = env.render(mode = 'rgb_array')
im.set_data(frame)
frames.append(frame)
if done:
env.reset()
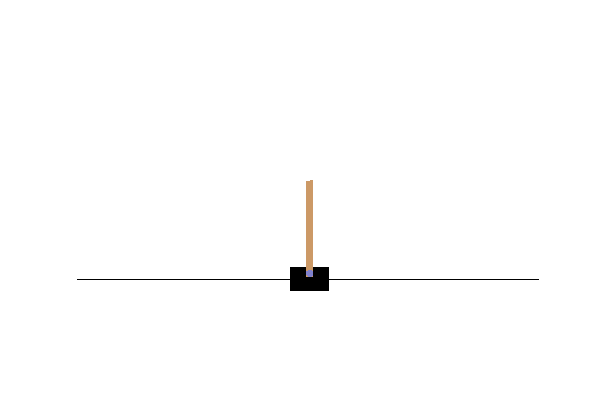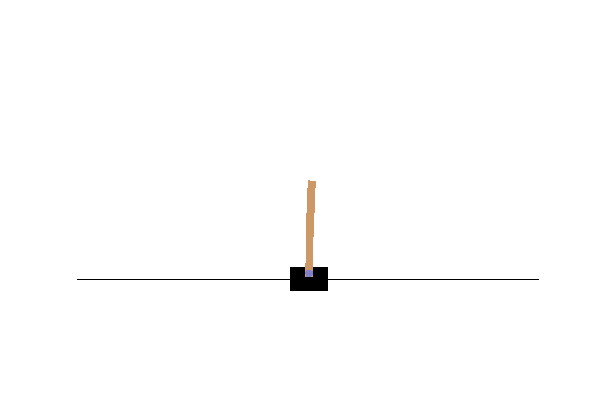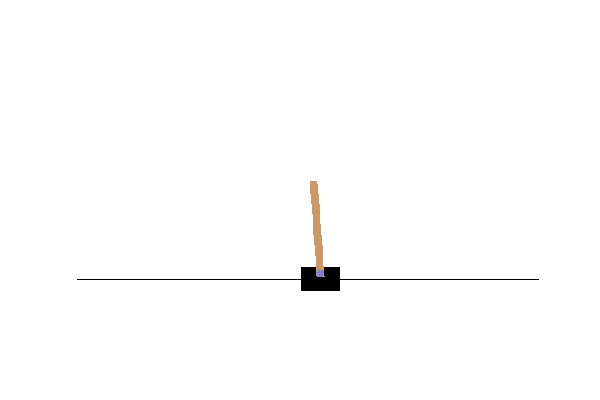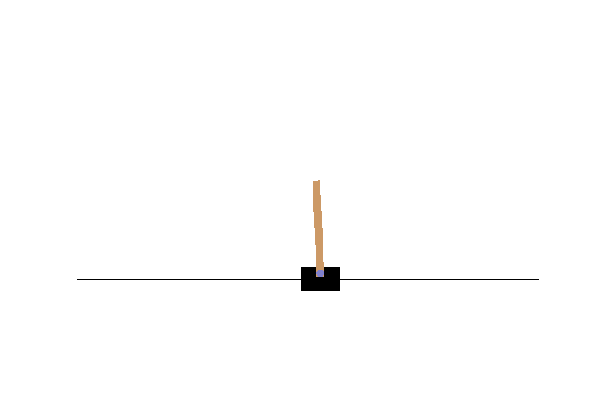
Replay
Now that you toyed around you probably want to see a replay. Every button click we saved the state of the game, which you can display in your browser:
def display_frames_as_gif(frames, filename_gif = None):
"""
Displays a list of frames as a gif, with controls
"""
plt.figure(figsize=(frames[0].shape[1] / 72.0, frames[0].shape[0] / 72.0), dpi = 72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames = len(frames), interval=50)
if filename_gif:
anim.save(filename_gif, writer = 'imagemagick', fps=20)
display(display_animation(anim, default_mode='loop'))
display_frames_as_gif(frames, filename_gif="manualplay.gif")
Representation
The cartpole environment is described on the OpenAI website. The values in the observation parameter show position (x), velocity (x_dot), angle (theta), and angular velocity (theta_dot). If the pole has an angle of more than 15 degrees, or the cart moves more than 2.4 units from the center, the game is “over”. The environment can then be reset by calling env.reset().
Start learning
This blogpost would be incomplete without a simple “learning” mechanism. Kevin Frans made a great blogpost about simple algorithms you can apply on this problem: http://kvfrans.com/simple-algoritms-for-solving-cartpole/.
The simplest one to implement is his random search algorithm. By multiplying parameters with the observation parameters the cart either decides to apply the force left or right. Now the question is: what are the best parameters? Random search defines them at random, sees how long the cart lasts with those parameters, and remembers the best parameters it found.
def run_episode(env, parameters):
"""Runs the env for a certain amount of steps with the given parameters. Returns the reward obtained"""
observation = env.reset()
totalreward = 0
for _ in xrange(200):
action = 0 if np.matmul(parameters,observation) < 0 else 1
observation, reward, done, info = env.step(action)
totalreward += reward
if done:
break
return totalreward
# Random search: try random parameters between -1 and 1, see how long the game lasts with those parameters
bestparams = None
bestreward = 0
for _ in xrange(10000):
parameters = np.random.rand(4) * 2 - 1
reward = run_episode(env,parameters)
if reward > bestreward:
bestreward = reward
bestparams = parameters
# considered solved if the agent lasts 200 timesteps
if reward == 200:
break
def show_episode(env, parameters):
""" Records the frames of the environment obtained using the given parameters... Returns RGB frames"""
observation = env.reset()
firstframe = env.render(mode = 'rgb_array')
frames = [firstframe]
for _ in xrange(200):
action = 0 if np.matmul(parameters,observation) < 0 else 1
observation, reward, done, info = env.step(action)
frame = env.render(mode = 'rgb_array')
frames.append(frame)
if done:
break
return frames
frames = show_episode(env, bestparams)
display_frames_as_gif(frames, filename_gif="bestresultrandom.gif")
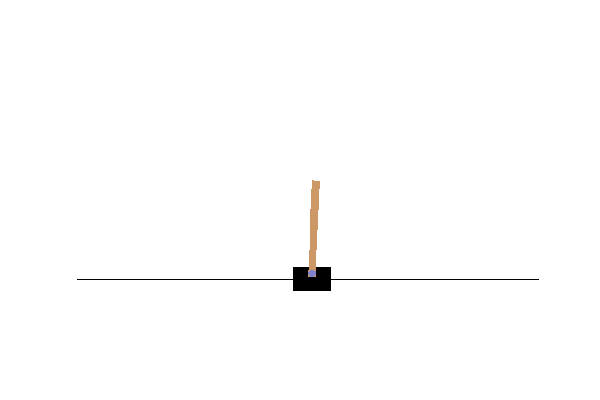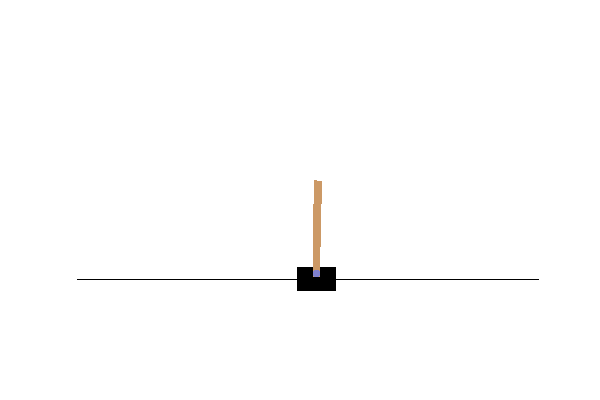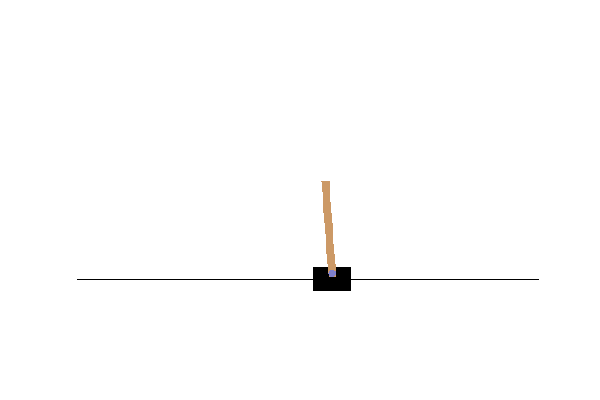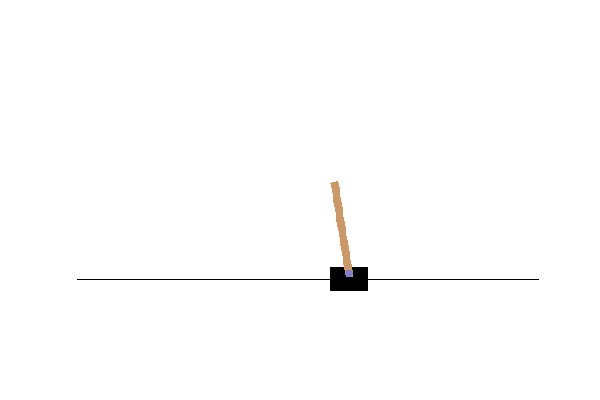
Exercises to learn more about OpenAI gym
The next step is to play and learn yourself. Here are some suggestions:
- Continue with the tutorial Kevin Frans made: http://kvfrans.com/simple-algoritms-for-solving-cartpole/
- Upload and share your results. Compare how well either the random algorithm works, or how well the algorithm you implemented yourself works compared to others. How you can do this can be found on this page: https://gym.openai.com/docs#recording-and-uploading-results under the heading “Recording and uploading results”
- Take a look at the other environments: https://gym.openai.com/envs . If you can solve the cartpole environment you can surely also solve the Pendulum problem (note that you do have to adjust your algorithm, as this one only has 3 variables in its observation).
Conclusion
Congratulations! You made your first autonomous pole-balancer in the OpenAI gym environment. Now that this works it is time to either improve your algorithm, or start playing around with different environments. This Jupyter notebook skips a lot of basic knowledge about what you are actually doing, there is a great writeup about that on the OpenAI site.
Unless you decided to make your own algorithm as an exercise you will not have done a lot of machine learning this tutorial (I don’t consider finding random parameters “learning”). Next session we will take a look at deep q networks: neural networks that predict the reward of each action.
Acknowledgments
This blogpost is the first part of my TRADR summerschool workshop on using human input in reinforcement learning algorithms. More information can be found on their homepage
Hi, I tried running the first part of the code but I am unable to play cart pole myself, I can only get the bot to play it. Do you have any idea why this might be?
I noticed sometimes people don’t see the buttons that are added to the notebook. Do they show up for you? And can you click them?
I had expected continuous motion. The cart moves one step with each click. (This is not real time balancing!) I added the line
print “x-pos: “, observation[0], “reward: “, reward, “done: “, done
in onClick after the call to env.step.
I also added print “Resetting” to the env.reset branch.
A sequence of right-arrow clicks produced the following.
x-pos: -0.0379549795827 reward: 1.0 done: False
x-pos: -0.0350037626123 reward: 1.0 done: False
x-pos: -0.0281463496415 reward: 1.0 done: False
x-pos: -0.0173812220226 reward: 1.0 done: False
x-pos: -0.00270551595161 reward: 1.0 done: False
x-pos: 0.0158845723922 reward: 1.0 done: False
x-pos: 0.0383931674471 reward: 1.0 done: False
x-pos: 0.0648238433954 reward: 1.0 done: False
x-pos: 0.095178456252 reward: 1.0 done: True
Resetting
x-pos: -0.019234806825 reward: 1.0 done: False
x-pos: -0.0157133089794 reward: 1.0 done: False
x-pos: -0.00829965501693 reward: 1.0 done: False
x-pos: 0.00300822525208 reward: 1.0 done: False
x-pos: 0.0182139759978 reward: 1.0 done: False
x-pos: 0.0373224606199 reward: 1.0 done: False
x-pos: 0.0603392254992 reward: 1.0 done: False
x-pos: 0.087269744135 reward: 1.0 done: False
x-pos: 0.11811839382 reward: 1.0 done: False
x-pos: 0.152887111764 reward: 1.0 done: True
Resetting
x-pos: 0.0181994194178 reward: 1.0 done: False
x-pos: 0.0215541741017 reward: 1.0 done: False
x-pos: 0.0288145326113 reward: 1.0 done: False
x-pos: 0.0399819311932 reward: 1.0 done: False
x-pos: 0.0550591826888 reward: 1.0 done: False
x-pos: 0.0740500871008 reward: 1.0 done: False
x-pos: 0.0969588314145 reward: 1.0 done: False
x-pos: 0.123789142134 reward: 1.0 done: False
x-pos: 0.154543145255 reward: 1.0 done: True
Resetting
x-pos: -0.0255643661693 reward: 1.0 done: False
So it seems the starting point is not the same each time, and the displacement required to “lose” is not the same either. (It doesn’t look like 2.4 units.)
How do you execute the code?