In part 1 we used a random search algorithm to “solve” the cartpole environment. This time we are going to take things to the next level and implement a deep q-network.The OpenAI gym environment is one of the most fun ways to learn more about machine learning. Especially reinforcement learning and neural networks can be applied perfectly to the benchmark and Atari games collection that is included.Every environment has multiple featured solutions, and often you can find a writeup on how to achieve the same score. By looking at others approaches and ideas you can improve yourself quickly in a fun way.
In part 1 we introduced the Gym environment, and looked at a “random search” algorithm. Hopefully you were able to add something to this algorithm, and got some more experience with OpenAI Gym. In part two we are going to take a look at reinforcement learning algorithms, specifically the deep q-networks that are all the hype lately.
Background
Q-learning is a reinforcement learning technique that tries to predict the reward of a state-action pair. For the cartpole environment the state consists of four values, and there are two possible actions. For a certain state S we can predict the reward if we were to push left ")
")
In the Atari game environment you get a reward of 1 every time you score a point. This scoring can happen when you hit a block in breakout, an alien in Space Invaders, or eat a pallet in Pacman. In the cartpole environment you get a reward every time the pole is standing on the cart (which is: every frame). The trick of q-learning is that it not only considers the direct reward, but also the expected future reward. After applying action 

- The reward
we obtained by performing this action
- The expected maximum reward
, in the cartpole environment this is
, Q(S_{t+1},right)")
We combine this into a neat formula where say that the predicted value should be
![]()
Where 
This notebook can be found in my prepared docker environment. If you did not install Docker yet, make sure you do this. To run this environment type this in your terminal:
docker run -p 8888:8888 rmeertens/tensorflowgymThen navigate to localhost:8888 and navigate to the TRADR folder.
Let’s apply our knowledge of q-learning on the same environment we tried last time: the CartPole environment.
%matplotlib notebook
from time import gmtime, strftime
import threading
import time
import numpy as np
import matplotlib.pyplot as plt
from ipywidgets import widgets
from IPython.display import display
import tensorflow as tf
import gym
from gym import wrappers
import random
from matplotlib import animation
from JSAnimation.IPython_display import display_animation
env = gym.make('CartPole-v0')
observation = env.reset()
Value approximation
There are many ways in which you can estimate the Q-value for each (state,action) pair. Neural networks have been really popular the last couple of years, so we are going to estimate the Q-value using a neural network.
We will build our network in Tensorflow: an open-source libary for machine-learning. If you are not familiar with Tensorflow, the most important thing to know is that we will fist build our network, then initialise it and use it. All python variables are “placeholders” in a session. You can find more information on the Tensorflow homepage
I created a very simple network layout with four inputs (the four variables we observe) and two outputs (either push left or right). I added four fully connected layers:
- From 4 to 16 variables
- From 16 to 32 variables
- From 32 to 8 variables
- From 8 to 2 variables
Every layer is a dense layer with a RELU nonlinearity except for the last layer as this one has to predict the expected Q-value.
# Network input
networkstate = tf.placeholder(tf.float32, [None, 4], name="input")
networkaction = tf.placeholder(tf.int32, [None], name="actioninput")
networkreward = tf.placeholder(tf.float32,[None], name="groundtruth_reward")
action_onehot = tf.one_hot(networkaction, 2, name="actiononehot")
# The variable in our network:
w1 = tf.Variable(tf.random_normal([4,16], stddev=0.35), name="W1")
w2 = tf.Variable(tf.random_normal([16,32], stddev=0.35), name="W2")
w3 = tf.Variable(tf.random_normal([32,8], stddev=0.35), name="W3")
w4 = tf.Variable(tf.random_normal([8,2], stddev=0.35), name="W4")
b1 = tf.Variable(tf.zeros([16]), name="B1")
b2 = tf.Variable(tf.zeros([32]), name="B2")
b3 = tf.Variable(tf.zeros([8]), name="B3")
b4 = tf.Variable(tf.zeros(2), name="B4")
# The network layout
layer1 = tf.nn.relu(tf.add(tf.matmul(networkstate,w1), b1), name="Result1")
layer2 = tf.nn.relu(tf.add(tf.matmul(layer1,w2), b2), name="Result2")
layer3 = tf.nn.relu(tf.add(tf.matmul(layer2,w3), b3), name="Result3")
predictedreward = tf.add(tf.matmul(layer3,w4), b4, name="predictedReward")
# Learning
qreward = tf.reduce_sum(tf.multiply(predictedreward, action_onehot), reduction_indices = 1)
loss = tf.reduce_mean(tf.square(networkreward - qreward))
tf.summary.scalar('loss', loss)
optimizer = tf.train.RMSPropOptimizer(0.0001).minimize(loss)
merged_summary = tf.summary.merge_all()
Session management and Tensorboard
Now we start the session. I added support for Tensorboard: a nice tool to visualise your learning. At the moment I only added one summary: the loss of the network.
If you did not install Docker yet, make sure you do this. To run tensorboard you have to run:
docker run -p 6006:6006 -v $(pwd):/mounted rmeertens/tensorboardThen navigate to localhost:6006 to see your tensorboard.
sess = tf.InteractiveSession()
summary_writer = tf.summary.FileWriter('trainsummary',sess.graph)
sess.run(tf.global_variables_initializer())
Learning Q(S,a)
An interesting paper you can use as guideline for deep q-networks is “Playing Atari with Deep Reinforcement Learning (https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf). This paper by deepmind explains how they were able to teach a neural network to play Atari games.
One of the main contributions of this paper is their use of an “experience replay mechanism”. If you were to train your neural network in the order of images you see normally the network quickly forgets what it saw before. To fix this we save what we saw in a memory with the following variables:
(



Now every frame we sample a random minibatch of our memory and train our network on that. We also only keep the newer experiences to keep our memory fresh with good actions. The full algorithm in their paper looks like this:

replay_memory = [] # (state, action, reward, terminalstate, state_t+1)
epsilon = 1.0
BATCH_SIZE = 32
GAMMA = 0.9
MAX_LEN_REPLAY_MEMORY = 30000
FRAMES_TO_PLAY = 300001
MIN_FRAMES_FOR_LEARNING = 1000
summary = None
for i_epoch in range(FRAMES_TO_PLAY):
### Select an action and perform this
### EXERCISE: this is where your network should play and try to come as far as possible!
### You have to implement epsilon-annealing yourself
action = env.action_space.sample()
newobservation, reward, terminal, info = env.step(action)
### I prefer that my agent gets 0 reward if it dies
if terminal:
reward = 0
### Add the observation to our replay memory
replay_memory.append((observation, action, reward, terminal, newobservation))
### Reset the environment if the agent died
if terminal:
newobservation = env.reset()
observation = newobservation
### Learn once we have enough frames to start learning
if len(replay_memory) > MIN_FRAMES_FOR_LEARNING:
experiences = random.sample(replay_memory, BATCH_SIZE)
totrain = [] # (state, action, delayed_reward)
### Calculate the predicted reward
nextstates = [var[4] for var in experiences]
pred_reward = sess.run(predictedreward, feed_dict={networkstate:nextstates})
### Set the "ground truth": the value our network has to predict:
for index in range(BATCH_SIZE):
state, action, reward, terminalstate, newstate = experiences[index]
predicted_reward = max(pred_reward[index])
if terminalstate:
delayedreward = reward
else:
delayedreward = reward + GAMMA*predicted_reward
totrain.append((state, action, delayedreward))
### Feed the train batch to the algorithm
states = [var[0] for var in totrain]
actions = [var[1] for var in totrain]
rewards = [var[2] for var in totrain]
_, l, summary = sess.run([optimizer, loss, merged_summary], feed_dict={networkstate:states, networkaction: actions, networkreward: rewards})
### If our memory is too big: remove the first element
if len(replay_memory) > MAX_LEN_REPLAY_MEMORY:
replay_memory = replay_memory[1:]
### Show the progress
if i_epoch%100==1:
summary_writer.add_summary(summary, i_epoch)
if i_epoch%1000==1:
print("Epoch %d, loss: %f" % (i_epoch,l))
Testing the algorithm
Now we have a trained network that gives use the expected ")
def display_frames_as_gif(frames, filename_gif = None):
"""
Displays a list of frames as a gif, with controls
"""
plt.figure(figsize=(frames[0].shape[1] / 72.0, frames[0].shape[0] / 72.0), dpi = 72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames = len(frames), interval=50)
if filename_gif:
anim.save(filename_gif, writer = 'imagemagick', fps=20)
display(display_animation(anim, default_mode='loop'))
### Play till we are dead
observation = env.reset()
term = False
predicted_q = []
frames = []
while not term:
rgb_observation = env.render(mode = 'rgb_array')
frames.append(rgb_observation)
pred_q = sess.run(predictedreward, feed_dict={networkstate:[observation]})
predicted_q.append(pred_q)
action = np.argmax(pred_q)
observation, _, term, _ = env.step(action)
### Plot the replay!
display_frames_as_gif(frames,filename_gif='dqn_run.gif')
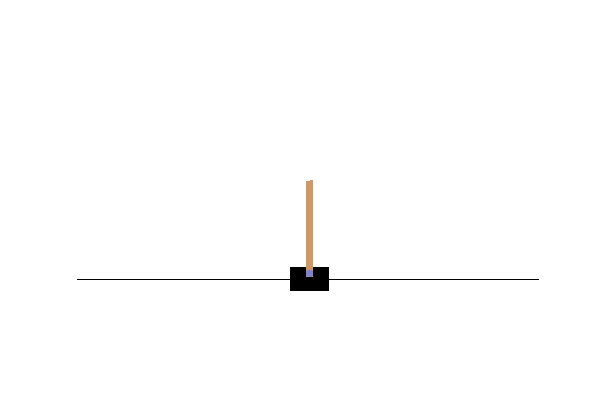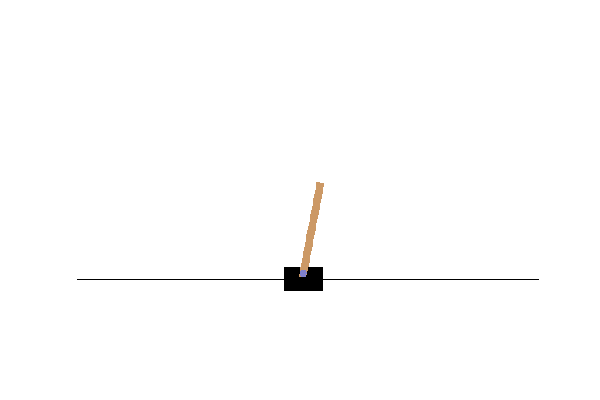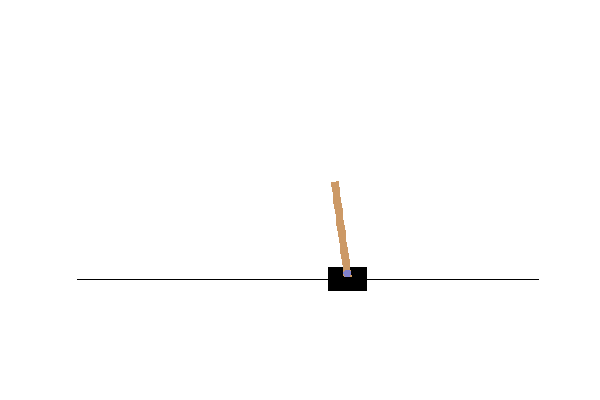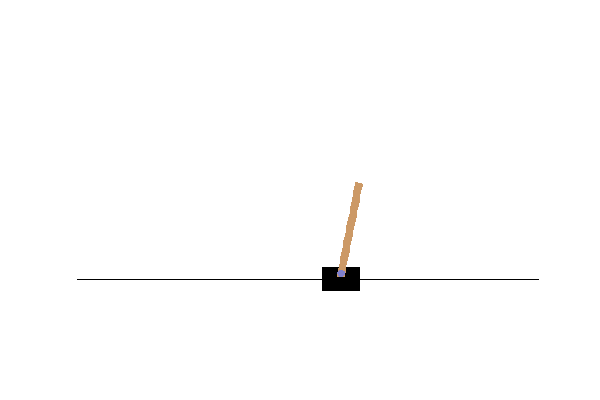
Result
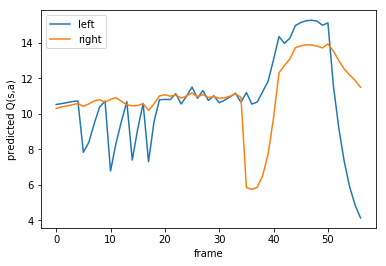
During this run on my pc the robot learns to compensate… but then overcompensates and dies. We can plot the Q-value the robot expected for each action(left or right) during the training.
plt.plot([var[0] for var in predicted_q])
plt.legend(['left', 'right'])
plt.xlabel("frame")
plt.ylabel('predicted Q(s,a)')
Handling difficult situations – team up with your robot
You can see in the graph above that our q-function, without the final mistake it made, has a good idea how well it is doing. At moments the pole is going sideways the maximum expected reward lowers. This is a good moment to team up with your robot and guide him when he is in trouble.
Collaborating is easy: if your robot does not know what to do, we can ask the user to provide input. The initial state the robot is in gives us a lot of information: ")

Note that in the graph above the agent died, even though it expected a lot of reward. This method is not foolproof, but does help the agent to survive longer.
%matplotlib inline
plt.ion()
observation = env.reset()
### We predict the reward for the initial state, if we are slightly below this ideal reward, let the human take over.
TRESHOLD = max(max(sess.run(predictedreward, feed_dict={networkstate:[observation]})))-0.2
TIME_DELAY = 0.5 # Seconds between frames
terminated = False
while not terminated:
### Show the current status
now = env.render(mode = 'rgb_array')
plt.imshow(now)
plt.show()
### See if our agent thinks it is safe to move on its own
pred_reward = sess.run(predictedreward, feed_dict={networkstate:[observation]})
maxexpected = max(max(pred_reward))
if maxexpected > TRESHOLD:
action = np.argmax(pred_reward)
print("Max expected: " + str(maxexpected))
time.sleep(TIME_DELAY)
else:
### Not safe: let the user select an action!
action = -1
while action < 0:
try:
action = int(raw_input("Max expected: " + str(maxexpected) + " left (0) or right(1): "))
print("Performing: " + str(action))
except:
pass
### Perform the action
observation, _, terminated, _ = env.step(action)
print("Unfortunately, the agent died...")
Exercises
Now that you and your neural network can balance a stick there are many things you can do to improve. As everyones skills are different I wrote down some ideas you can try:
Machine learning starter:
-
- Improve the neural network. You can toy around with layers (size, type), tune the hyperparameters, or many more.
- Toy around with the value of gamma, visualise for several values what kind of behaviour the agent will exercise. Is the agent more careful with a higher gamma value?
Tensorflow starter:
-
- If you don’t have a lot of experience you can either try to improve the neural network, or you can experiment with the Tensorboard tool. Try to add plots of the average reward during training. If you implemented epsilon-greedy exploration this number should go up during training.
Reinforcement learning starter:
-
- Because our agent only performs random actions our network dies pretty often during training. This means that it has a good idea what to do in its start configurations, but might have a problem when it survived for a longer time. Epsilon-greedy exploration prevents this. With this method you roll a die: with probability epsilon you take a random action, otherwise you take the action the agent thinks is best. You can either set epsilon to a specific value (0.25? 0.1?) or gradually take a lower value to encourage exploration.
- Team up with your agent! We already help our agent when he thinks he is in a difficult situation, we could also let it ask for help during training. By letting the agent ask for help with probability epsilon you explore the state space in a way that makes more sense than random exploration, and this will give you a better agent.
Reinforcement learning itermediate:
- Right now we only visualise the loss, which is no indication for how good the network is. According to the paper Playing Atari with Deep Reinforcement Learning the average expected
- Artur Juliani suggests that you can use a target network. During training your network is very “unstable”, it “swings” in all directions which can take a long time to converge. You can add a second neural network (exactly the same layout as the first one) that calculates the predicted reward. During training, every
frames, you set the weights of your target network equal to the weights of your other network.
Conclusion
In part two we implemented a deep q-network in Tensorflow, and used it to control a cartpole. We saw that the network can “know” when it has problems, and then teamed up with our agent to help him out. Hopefully you enjoyed working with neural networks, the OpenAI gym, and working together with your agent.
Initially I wanted to dive into the Atari game environments and skip the CartPole environment for the deep q-networks. Unfortunately, training takes too long (24 hours) before the agent is capable of exercising really cool moves. As I still think it is a lot of fun to learn how to play Atari games I made a third part with some exercises you can take a look at.
Acknowledgments
This blogpost is the first part of my TRADR summerschool workshop on using human input in reinforcement learning algorithms. More information can be found on their homepage.
I love to receive your (anonymous) comments! (0)
Facebook Comments (0)
G+ Comments (0)