On 9 and 10 February, the 2017 edition of CLIN (Computational Linguistics in the Netherlands) was held. As I work a lot with neural machine translation, automatic post editing, and translation quality estimation, this conference was very interesting to me! This post is a write-up of the most interesting talks I attended.
At the moment neural methods are hot, also in the Computational Linguistics world. Interesting is that many people using neural methods ignore linguistics completely. The keynote speaker, Ann Copestake, discussed this matter. What I took away from her talk was mainly that it would be interesting if linguists would start to use neural networks to try to learn HOW they acquire language, and what this says about our own language acquisition.
The BLEU metric
On Thursday Mikel Forcada gave a talk in which he analyzed the use of metrics to assess translation quality. At the moment the BLEU score is used in most papers. This score assesses the translation quality of a sentence by looking at a number of adjacent words that match a “perfect translation” (often created by a human translator). Although it has been known for many years that this metric does not always follow human judgment, people keep using it.
Personally, I think that at the moment BLEU is the best there is for some applications until people discover a better metric (for example at the WMT conference). However, Mikel is right that often there might be other data that could be used. For example, at the company I work at we could try to measure post-editing times for sentences we pre-translated. By translating part of these sentences with algorithm A, and another part with algorithm B, we can a better effect in what really matters: helping translators do their job.
Another interesting observation Mikel made was that most researchers building a machine translation system test their software by measuring the BLEU score on the same dataset (Penn Treebank). As many people conducted experiments on this dataset, a researcher gaining a “point” should not be considered significant anymore.
Deep learning at CLIN
As can be expected many people at CLIN were using neural networks some way. Especially Mikolovs Word2Vec tool was used by many people. Unknown to me and the people with whom I talked, this tool did not always improve results with the Dutch language. If you have an opinion on this, I would love to know.
For me, the most interesting talk of the deep learning track was the one by Neculoiu, Versteegh, Rotaru. At their company Textkernel, they have the problem people use many different names to describe their profession. For example, I could describe myself as a deep learning engineer, neural network engineer, or researcher neural networks. All these names represent the same thing: I like to work with deep neural networks. Although sometimes there is an overlap in words within the category (in the example the word “neural”), sometimes there is no overlap at all (e.g. deep learning engineer). They took on the challenge of constructing a system that the name of a profession, and determines the category.
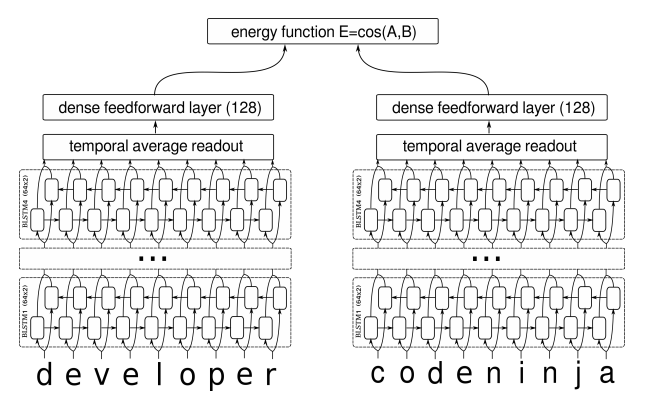
To do this, they feed both character names in a neural network that goes over the name 8 times (4 times, left to right and right to left, using an LSTM). The representation this gives is put through another neural network that determines a “distance” between two words. If the distance is small, they belong to the same category. Some categories they automatically determined, and a diagram of their network can be seen below this paragraph. The paper they published about this is very interesting and can be found here: http://anthology.aclweb.org/W16-1617 .
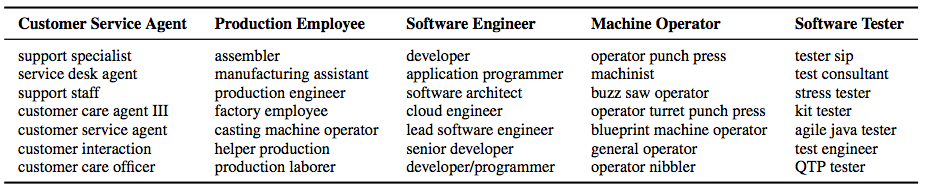
Conclusion
Visiting CLIN was a great experience. Unfortunately, describing every interesting talk I saw would lead to a way too lengthy article. I met many people, with whom I had interesting discussions. The talks I attended were great, and the city of Leuven was simply beautiful. During my visit, I got so many ideas that I am eager to implement. If you talked with me at CLIN 2017, or have any questions, don’t be afraid to contact me.
Facebook Comments (
G+ Comments ()