
In 1998 Nintendo released the Gameboy Camera. With this camera, it was possible to take images in a resolution of 256×224 pixels (or 0.05734 megapixels). The screen resized your image to 190×144 pixels and shows it in 4 shades of gray/green. Despite these limitations images you took are recognizable for us humans. In this post, I show my adventures in creating photorealistic camera images using Deep Neural Networks!
Inspiration
Recently several applications of convolutional neural networks have been discovered. Examples are super-resolution (upscaling an image without loss), coloring (from grayscale to RGB), and removing (JPEG) compression artifacts. Other examples are real-time style transfer and turning sketches into photorealistic face images, discovered by Yağmur Güçlütürk, Umut Güçlü, Rob van Lier, and Marcel van Gerven. This last example inspired me to take Gameboy camera images of faces and turn them into photorealistic images.
Summary of my experiment
Back in 1998, the Gameboy camera got the world record as “smallest digital camera” in the Guinness book of records. An accessory you could buy was the small printer you could use to print your images. When I was 10 years old we had one of these cameras at home and used it a lot. Although we did not have the printer, taking pictures, editing them, and playing minigames was a lot of fun. Unfortunately, I could not find my old camera (no colored young Roland pictures, unfortunately), but I did buy a new one so I could test my application.
In the end the result turned out very good. The generated images are really great. Although we trained on a small part of the face even pictures of whole heads seem to turn out nice. The following images are images the network has never seen before. The image in the center is the “real image”, the image on the right is generated by our neural network. Note that even skincolor is accurate most of the times.




These are some images that were shot with the gameboy camera, and uploaded by random people.


And… My face, shot with a gameboy camera.

In this blog post, I will guide you through my progress of this project. Some boring parts are hidden but can be expanded for the full story. With the code, you should be able to replicate the results. A Git repository can be found here.
Training data
Unfortunately, there is no training data set with Gameboy-camera images of faces together with the real picture of the person. To create a dataset I made a function that takes an image as input and creates an image with 4 shades of black. The shade is based on the mean and standard deviation of the image, to make sure that we always use 4 colors. If you look at original Gameboy camera images you can see that they create gradients by alternating pixels to give the illusion of more colors. To immitate this I simply added noise on top of my original images. Note that if you want to experiment you can change the apply_effect_on_folder function to create images from sketches instead of Gameboy camera images.
%matplotlib inline
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import IPython.display as ipyd
import os
import random
import pickle
import cv2
from sklearn.decomposition import PCA
from libs import vgg16 # Download here! https://github.com/pkmital/CADL/tree/master/session-4/libs
from libs import gif
from libs import utils
IMAGE_PATH = "/home/roland/img_align_celeba_png" # DOWNLOAD HERE! http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
TEST_IMAGE_PATH = '/home/roland/workspace/gameboy_camera/test_images'
PICTURE_DATASET = os.listdir(IMAGE_PATH)
PREPROCESSED_IMAGE_PATH = "/home/roland/img_align_celeba_effect"
PROCESSED_PICTURE_DATASET = os.listdir(PREPROCESSED_IMAGE_PATH)
IMAGE_WIDTH = 96
IMAGE_HEIGHT = 96
COLOR_CHANNEL_COUNT = 3
NORMALISE_INPUT = False
def load_random_picture_from_list(image_names,path):
index_image = random.randint(0,len(image_names)-1)
name_picture = image_names[index_image]
path_file = os.path.join(path,name_picture)
image = plt.imread(path_file)
return image
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
def add_sketch_effect(image):
img_gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
img_gray_inv = 255 - img_gray
img_blur = cv2.GaussianBlur(img_gray_inv, ksize=(5, 5),sigmaX=0, sigmaY=0)
img_blend = dodgeV2(img_gray, img_blur)
ret,img_blend = cv2.threshold(img_blend,240,255,cv2.THRESH_TRUNC)
return img_blend
def add_gameboy_camera_effect(image):
img_gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
mean = np.mean(img_gray)
stdev = np.std(img_gray)
random_noise = np.random.random_sample(size=img_gray.shape)/10
img_gray += random_noise
lowest = img_gray < (mean-stdev)
second = (img_gray < (mean))
third = (img_gray < (mean+stdev))
highest = (img_gray >= 0.0)-third
pallet = np.zeros(img_gray.shape,dtype=np.float32)
pallet[highest]=1.0
pallet[third]=0.66
pallet[second]=0.33
pallet[lowest]=0.0
return pallet
def dodgeV2(image, mask):
return cv2.divide(image, 255-mask, scale=256)
def burnV2(image, mask):
return 255 - cv2.divide(255-image, 255-mask, scale=256)
def resize_image_by_cropping(image,width,height):
"""Resizes image by cropping the relevant part out of the image"""
original_height = len(image)
original_width = len(image[0])
start_h = (original_height - height)//2
start_w = (original_width - width)//2
return image[start_h:start_h+height,start_w:start_w+width]
def apply_effect_on_folder(name_input_folder,name_output_folder):
picture_names = os.listdir(name_input_folder)
i = 0
for name_picture in picture_names:
i+=1
if i % 250==1:
print(i)
print(len(picture_names))
path_file = os.path.join(IMAGE_PATH,name_picture)
image = plt.imread(path_file)
image = resize_image_by_cropping(image)
effect = add_gameboy_camera_effect(image)
write_path_original = os.path.join(name_output_folder,name_picture+".orig")
write_path_effect = os.path.join(name_output_folder,name_picture+".effect")
np.save(write_path_original,image)
np.save(write_path_effect,effect)
def load_names_images():
names_images = [a[:6] for a in PROCESSED_PICTURE_DATASET]
names_images = list(set(names_images))
orig = [a+".png.orig.npy" for a in names_images]
effect = [a+".png.effect.npy" for a in names_images]
return list(zip(orig,effect))
def normalise_image(image,mean,stdev):
normalised = (image-mean)/stdev
return normalised
def normalise_numpy_images(images,mean,stdev):
return np.array([normalise_image(image,mean,stdev) for image in images])
def denormalise_image(image,mean,stdev):
return image*mean+stdev
class PreprocessedImageLoader:
def get_random_images_from_set(self,count,names_images):
Xs = []
Ys = []
random.shuffle(names_images)
names_images_batch = names_images[:count]
for name_image in names_images_batch:
index = random.randint(0,len(names_images)-1)
name_orig = os.path.join(self.path,name_image[0])
name_effect = os.path.join(self.path,name_image[1])
Xs.append( np.load(name_effect))
Ys.append( np.load(name_orig))
return np.array(Xs),np.array(Ys)
def get_train_images(self,count):
return self.get_random_images_from_set(count,self.trainimage_names)
def get_test_images(self,count):
return self.get_random_images_from_set(count,self.testimage_names)
def __init__(self,path,image_names,trainsplit_ratio=0.8):
assert trainsplit_ratio > 0.0
assert trainsplit_ratio < 1.0
self.path = path
self.trainimage_names = names_images[:int(trainsplit_ratio*len(image_names))]
self.testimage_names = names_images[int(trainsplit_ratio*len(image_names)):]
#apply_effect_on_folder(IMAGE_PATH,PREPROCESSED_IMAGE_PATH)
names_images = load_names_images()
imageloader = PreprocessedImageLoader(PREPROCESSED_IMAGE_PATH,names_images)
source_x, test_y = imageloader.get_test_images(10)
fig = plt.figure()
plt.subplot(121)
plt.imshow(source_x[0],cmap='gray')
plt.subplot(122)
plt.imshow(test_y[0])
plt.show()

As you can see the random noise on top of the image creates the “gradients” you see in the gameboy camera images that give the illusion of more than 4 colors. Note that a downside of the crop function I programmed is that most of the background of the images is not really visible (even parts of the chin are hidden). This might give problems later if we try to feed the network images with more background.
Data preprocessing
The preprocessing step of the project is normalising the input images. Hidden is the code that loads 30.000 training images and calculates the mean and standard deviation of the gameboy images and the original images. Because it looks cool, this is the mean of the input and of the output:
name_save_mean_std = "mean_std_sketches.npy"
name_save_color_mean_std = "mean_std_color.npy"
if os.path.isfile(name_save_mean_std):
loaded_images = np.load(name_save_mean_std)
mean_sketch = loaded_images[0]
stdeviation_sketch = loaded_images[1]
loaded_images = np.load(name_save_color_mean_std)
mean_color = loaded_images[0]
stdeviation_color = loaded_images[1]
else:
TrainInput, TrainOutput = imageloader.get_train_images(30000)
sketches = np.array(TrainInput)
color_images = np.array(TrainOutput)
mean_sketch = np.mean(sketches,axis=0)
stdeviation_sketch = np.std(sketches,axis=0)
mean_color = np.mean(color_images,axis=0)
stdeviation_color = np.mean(color_images,axis=0)
to_save = np.array([mean_sketch,stdeviation_sketch])
np.save(name_save_mean_std,to_save)
to_save = np.array([mean_color,stdeviation_color])
np.save(name_save_color_mean_std,to_save)
def normalise_image(image,mean,stdev):
normalised = (image-mean)/stdev
return normalised
def normalise_numpy_images(images,mean,stdev):
return np.array([normalise_image(image,mean,stdev) for image in images])
def denormalise_image(image,mean,stdev):
return image*mean+stdev
if NORMALISE_INPUT:
test_x = normalise_numpy_images(source_x,mean_sketch,stdeviation_sketch)
else:
test_x = source_x
test_x = np.expand_dims(test_x,3)
progress_images = []
fig = plt.figure()
plt.subplot(121)
plt.imshow(mean_color)
plt.subplot(122)
plt.imshow(mean_sketch,cmap='gray')
plt.show()

Helper functions
To ease the programming I created several helper functions that create layers in my graph. There are two ways of “deconvolving” an image: either using the conv2d_transpose operation of Tensorflow, or resizing the image and doing a normal convolution after that.
During early experiment I used the conv2d_transpose function, but this resulted in images with strange patterns:


Thanks to this post http://distill.pub/2016/deconv-checkerboard/ I found out about the alternative deconvolution layer and implemented that one.
def conv_layer(input_image,ksize,in_channels,out_channels,stride,scope_name,activation_function=tf.nn.relu):
with tf.variable_scope(scope_name):
filter = tf.Variable(tf.random_normal([ksize,ksize,in_channels,out_channels],stddev=0.03))
output = tf.nn.conv2d(input_image,filter, strides=[1, stride, stride, 1], padding='SAME')
if activation_function:
output = activation_function(output)
return output, filter
def residual_layer(input_image,ksize,in_channels,out_channels,stride,scope_name):
with tf.variable_scope(scope_name):
output,out_weights = conv_layer(input_image,ksize,in_channels,out_channels,stride,scope_name+"conv1")
output,out_weights = conv_layer(output,ksize,out_channels,out_channels,stride,scope_name+"conv2")
cool_stuff = tf.add(output,tf.identity(input_image))
return cool_stuff,out_weights
def transpose_deconvolution_layer(input_tensor,used_weights,new_shape,stride,scope_name):
with tf.variable_scope(scope_name):
output = tf.nn.conv2d_transpose(input_tensor, used_weights, output_shape=new_shape,strides=[1,stride,stride,1], padding='SAME')
output = tf.nn.relu(output)
return output
def resize_deconvolution_layer(input_tensor,used_weights,new_shape,stride,scope_name):
with tf.variable_scope(scope_name):
output = tf.image.resize_images(input_tensor,(new_shape[1],new_shape[2]))#tf.nn.conv2d_transpose(input_tensor, used_weights, output_shape=new_shape,strides=[1,stride,stride,1], padding='SAME')
output, unused_weights = conv_layer(output,3,new_shape[3]*2,new_shape[3],1,scope_name+"_awesome_deconv")
return output
def deconvolution_layer(input_tensor,used_weights,new_shape,stride,scope_name):
return resize_deconvolution_layer(input_tensor,used_weights,new_shape,stride,scope_name)
def output_between_zero_and_one(output):
output +=1
return output/2
Loss functions
In the sketch-to-photorealistic-image paper and the real-time style transfer paper, the authors use three different loss functions: pixel-loss, content-loss, and a smoothing-loss. By using a pixel-loss you “teach” the network that the resulting colors are important. Unfortunately, using only this loss function gives very blurry images. With the content loss, you indicate that the image has to have the same “features” as the output image. The smoothing-loss gives a small penalty for neighboring pixels with big differences. I implemented the same three loss functions for my project.
def get_content_layer_vgg16(image):
net = vgg16.get_vgg_model()
content_layer = 'conv2_2/conv2_2:0'
feature_transformed_image = tf.import_graph_def(
net['graph_def'],
name='vgg',
input_map={'images:0': image},return_elements=[content_layer])
feature_transformed_image = (feature_transformed_image[0])
return feature_transformed_image
def get_content_loss(target,prediction):
feature_transformed_target = get_content_layer_vgg16(target)
feature_transformed_prediction = get_content_layer_vgg16(prediction)
feature_count = tf.shape(feature_transformed_target)[3]
content_loss = tf.reduce_sum(tf.square(feature_transformed_target-feature_transformed_prediction))
content_loss = content_loss/tf.cast(feature_count, tf.float32)
return content_loss
def get_smooth_loss(image):
batch_count = tf.shape(image)[0]
image_height = tf.shape(image)[1]
image_width = tf.shape(image)[2]
horizontal_normal = tf.slice(image, [0, 0, 0,0], [batch_count, image_height, image_width-1,3])
horizontal_one_right = tf.slice(image, [0, 0, 1,0], [batch_count, image_height, image_width-1,3])
vertical_normal = tf.slice(image, [0, 0, 0,0], [batch_count, image_height-1, image_width,3])
vertical_one_right = tf.slice(image, [0, 1, 0,0], [batch_count, image_height-1, image_width,3])
smooth_loss = tf.nn.l2_loss(horizontal_normal-horizontal_one_right)+tf.nn.l2_loss(vertical_normal-vertical_one_right)
return smooth_loss
def get_pixel_loss(target,prediction):
pixel_difference = target - prediction
pixel_loss = tf.nn.l2_loss(pixel_difference)
return pixel_loss
The network
The network consists of three convolutional layers for scaling the image down, two residual layers for adding/removing information, and three deconvolution layers for scaling the image back to the size we want it to be. There are some differences with the network described in the paper “Convolutional Sketch Inversion”. One thing I ignored is the batch normalisation layer. Although it is easy to add my network, this network already trained fast enough. Another difference is using only two residual layers, this is mostly because of my lack of computing power.
input_placeholder = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT,IMAGE_WIDTH,1])
output_placeholder = tf.placeholder(tf.float32,[None, IMAGE_HEIGHT,IMAGE_WIDTH,COLOR_CHANNEL_COUNT])
computed_batch_size = tf.shape(input_placeholder)[0]
conv1, conv1_weights = conv_layer(input_placeholder,9,1,32,1,"conv1")
conv2, conv2_weights = conv_layer(conv1,3,32,64,2,"conv2")
conv3, conv3_weights = conv_layer(conv2,3,64,128,2,"conv3")
res1, res1_weights = residual_layer(conv3,3,128,128,1,"res1")
res2, res2_weights = residual_layer(res1,3,128,128,1,"res2")
deconv1 = deconvolution_layer(res2,conv2_weights,[computed_batch_size,48,48,64],2,'deconv1')
deconv2 = deconvolution_layer(deconv1,conv3_weights,[computed_batch_size,96,96,32],2,'deconv2')
conv4, conv4_weights = conv_layer(deconv2,9,32,3,1,"last_layer",activation_function=tf.nn.tanh)
output = output_between_zero_and_one(conv4)
pixel_loss = get_pixel_loss(output_placeholder,output)
content_loss = get_content_loss(output_placeholder,output)
smooth_loss = get_smooth_loss(output)
content_factor = 1.0
pixel_factor = 1.0
smooth_factor = 0.0001
loss = pixel_factor*pixel_loss + content_factor*content_loss+smooth_factor*smooth_loss
optimizer = tf.train.AdamOptimizer().minimize(loss)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
def show_progress(input_image,target,generated):
fig = plt.figure()
plt.subplot(131)
plt.imshow(input_image,cmap='gray')
plt.subplot(132)
plt.imshow(target)
plt.subplot(133)
plt.imshow(generated)
plt.show()
Results
After explaining the image generation methods and network, it is time for running the network! It is really interesting to see the output of the network over time. You can see the generated image with the first image of my ‘test set’ at several moments during training. During training every 100 steps the same test image is converted to a photorealistic image. By creating a GIF out of these images you can see the progress of the network.
n_epochs = 5000
batch_size = 32
for epoch_i in range(n_epochs):
in_x, in_y = imageloader.get_train_images(batch_size)
if NORMALISE_INPUT:
in_x = normalise_numpy_images(in_x,mean_sketch,stdeviation_sketch)
in_x = np.expand_dims(in_x,3)
_,l = sess.run([optimizer,loss], feed_dict={input_placeholder:in_x ,output_placeholder: in_y })
if epoch_i % 100==1:
colored_images = sess.run(output, feed_dict={input_placeholder:test_x,output_placeholder:test_y})
generated = np.clip(colored_images,0.0,1.0)
generated = generated[0]
progress_images.append(generated)
if epoch_i < 800 or epoch_i > 19900:
show_progress(source_x[0],test_y[0],generated)
print("building progress gif out of " + str(len(progress_images)) + " images")
gif.build_gif(progress_images, interval=0.1, dpi=72, save_gif=True, saveto='animation.gif',show_gif=False)
ipyd.Image(url='animation.gif', height=200, width=200)








Interesting is that in the first iterations the skin colour of the generated image is off, but after seeing 9600 people the network learned the right colour. In the GIF it is interesting to look at the eyes and eyebrows who keep getting sharper and sharper (due to the content loss). In the sped up version gif you see lots of changes keep happening during time, indicating that maybe I could have benefited from a lower learning rate.
Testdata
To test my algorithm I tried to convert the following data using the trained network:
- testdata from the celebrity dataset
- images from people I found using Google Images by typing in “gameboy camera”
- faces that are in the gameboy camera (also found online)
- pictures of my face
Testdata from the celebrity dataset
for index,generated_image in enumerate(colored_images):
show_progress(source_x[index],test_y[index],generated_image)










This all looks pretty good to me. This was expected, as these images were taken with the same restrictions as the trainset.
Images from the internet
def show_colored_pictures(test_pictures):
for name_picture in test_pictures:
path_file = os.path.join(TEST_IMAGE_PATH,name_picture)
image = plt.imread(path_file)
image = cv2.resize(image,(96,96))
image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
in_x = np.array([image])
if NORMALISE_INPUT:
in_x = normalise_numpy_images(in_x,mean_sketch,stdeviation_sketch)
in_x = np.expand_dims(in_x,3)
colored_images = sess.run(output, feed_dict={input_placeholder:in_x})
fig = plt.figure()
plt.subplot(121)
plt.imshow(image,cmap='gray')
plt.subplot(122)
plt.imshow(colored_images[0])
plt.show()
test_pictures = ['test19.png','test18.png','test1.png','test2.png','test3.png']
show_colored_pictures(test_pictures)





I was impressed with how well these images turned out given that they do not follow the pattern as the train images. Even though the eyes are on a different spot, and a larger area was cropped around the face, I think the network created pretty good images.
Images from the gameboy itself
When trying to display an empty animation the gameboy camera has several faces it can display warning you that you have to create an animation first. I took two of these faces and tried colorizing them.
test_pictures = ['test4.png','test5.png']
show_colored_pictures(test_pictures)


Looks pretty good to me!
Images I took
A big problem trying to create color images from my own face was getting them off the gameboy camera. Buying the camera was easy, but finding a gameboy printer was impossible. Although somebody made a cable to put the images through the link cable on your pc, this also was impossible to find. What was left was the great method of taking images of the screen. A problem with this approach is that the lighting is always a lot off. As our network is trained on images that have equal lightning this posed a bit of a problem. This was a problem that was not easy to solve, and we have to do with colored images from noisy input.
test_pictures = ['test25.png','test27.png','test31.png']
show_colored_pictures(test_pictures)



In the end I’m quite happy with these results. The train images always have exactly 4 shades of black, and very specific noise patterns. In the self-made images the light is totally off, what should be white is pretty dark, and what should be dark is way too white. Especially in the last image you see a brightness gradient over the image. Yet, our algorithm is able to create a pretty good-looking face!
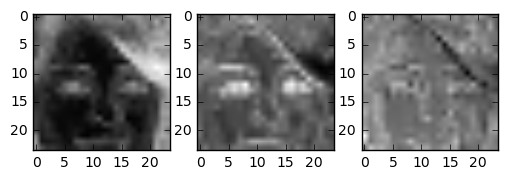
Output last deconvolution
To see what the network “learned” the activations in the last layer can be visualised.
last_layer = sess.run(deconv2, feed_dict={input_placeholder:test_x})
inspect_layer = last_layer[0]
last_layer_activations = []
for inspect_convolution_output in range(inspect_layer.shape[2]):
last_layer_activations.append(inspect_layer[:,:,inspect_convolution_output])
last_activation_montage = utils.montage(last_layer_activations)
plt.imshow(last_activation_montage,cmap='gray')
plt.show()

In this image you see all dimensions of the last deconv layer. Some layers encode large areas (hair, skin, background). Others encode tiny details such as the mouth or eyes.
PCA of each layer
As you can see the network seems to encode features such as hair, eyes, side of the face.
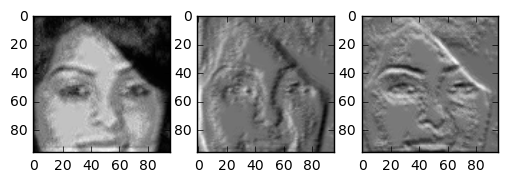
The last interesting thing I wanted to show is a visualising the principal components in each layer
all_steps = sess.run([input_placeholder,conv1,conv2,conv3,res1,res2,deconv1,deconv2,output], feed_dict={input_placeholder:test_x,output_placeholder:test_y})
for index_layer,layer in enumerate(all_steps[1:-1]):
print("Principal components output layer " + str(index_layer+1))
first_image = layer[0]
original_shape = first_image.shape
original_dimensions = original_shape[2]
first_image = np.reshape(first_image, (-1,original_dimensions))
pca = PCA(n_components=3)
fitted = pca.fit_transform(first_image)
fitted = np.reshape(fitted,(original_shape[0],original_shape[1],-1))
fig = plt.figure()
plt.subplot(131)
plt.imshow(fitted[:,:,0],cmap='gray')
plt.subplot(132)
plt.imshow(fitted[:,:,1],cmap='gray')
plt.subplot(133)
plt.imshow(fitted[:,:,2],cmap='gray')
plt.show()




>
The output of the principal components is both interesting and a bit obvious. The network learns to encode the skin, hair and background of the input images (just like we seen before).
Interesting observations/lessons learned
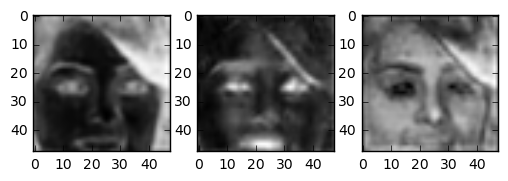
During this project I learned a lot of lessons. The lesson about different deconvolution layers is something I already described above. Another interesting lesson is that I started with normalising the output of the neural network.This yielded nice results early in training (outputting only zeros is already a good guess), but later this network had a lot of problems. The output of a barely trained network can be seen below. Unfortunately faces that were far away from the norm (i.e. people with hair in front of their face, sunglasses, people looking sideways) became blurry.


One question I asked myself was: how does this task compare to coloring sketch images? The details of the face are very blurry, but the outline of face details is still preserved. Because the areas between features are filled with 4 colours, the network has more grasp on what the resulting colour should compared to the line sketch problem. One interesting thing is that this network gives the right skincolor to people most of the time.
Conclusion
Create photorealistic color images from gameboy camera images is a possibility! Going from 0.05 megapixels 4-color-grayscale images to full-color faces is something convolutional neural networks can learn.
If you have other ideas for styles to convert from, or other things you would like to try, let me know. I am always willing to answer your questions. If you enjoyed reading this, please leave a comment or share this post to others who might be interested.
Update: somebody wanted to try out my network, and sent me an image taken with his gameboy camera. This is the result:

The colorized result of an image sent to me taken with his Gameboy Camera
great,very well, i need programe like this. Can you give me a whole programe that can process old or obscure photo.
So is there like a tool so we can do this ourself? I’m not that tech savy but would love some kind of program.
PS: love your work.