Google announced that it can do a zero-shot translation from Korean to Japanese and from Japanese to Korean. They do this without ever training on these language pairs, and without first translating to another language. Most people I spoke to did not get why this was so interesting. In this post I will explain what this means, and what this implies, with an analogy.
{kind=link}
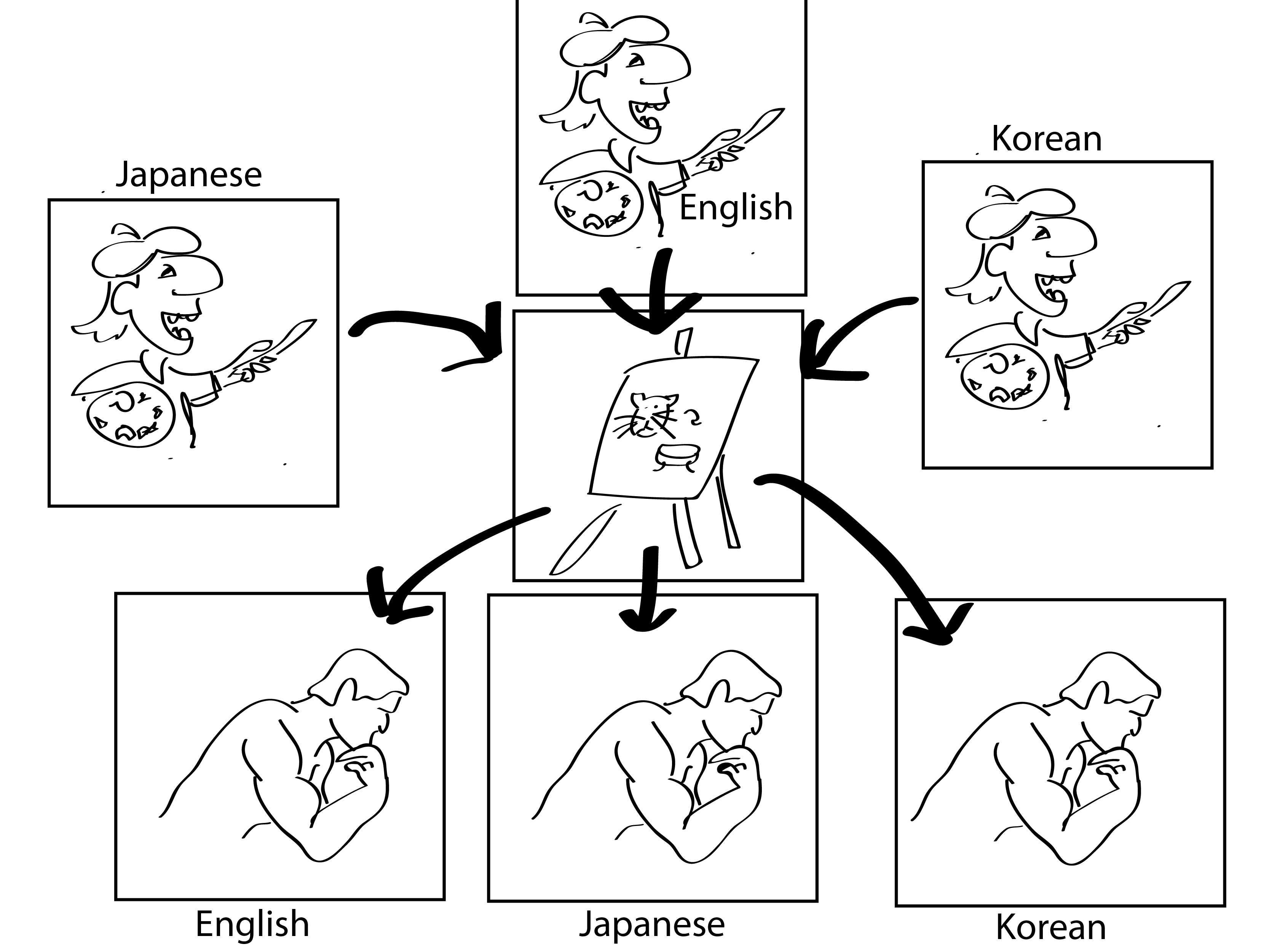
Image that you are playing a “translation game” with a friend. You read some text in a language you don’t (yet) understand, make a drawing out of it, and pass this to your friend in another room. He writes down text in a language he does not (yet) understand. Your friend gets feedback on what his text should have been, and may give feedback on the drawing you made as to what he expected.
Although you can imagine that it takes you both a long time, you and your friend start to understand these languages and start to see patterns in them. You can image that your drawings might not look very realistically, and often don’t convey the meaning of the sentence. Luckily, your friend will start to understand what you mean, and will give you valuable feedback.

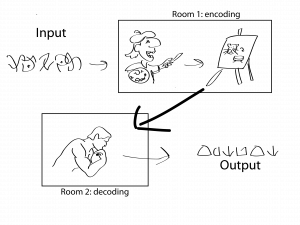
As an example: imagine we want to translate the sentence “tiger in a swimming pool. Maybe you discovered that one of the symbols is often used in a “cat-like” context, you can then draw a “cat-like” thing, and a ‘big water holding thing’ on your canvas. As your friend discovers that the word he had to write down was ‘tiger’ he will point out to you that you should have added stripes.

This is essentially the normal setup of a Neural Machine Translation engine. Two components learn a new language from scratch, while trying to settle on a way of representing (and thus communicating) the sentences they must translate. The “painting” in this analogy is not actually a painting, but a long row of numbers. As you can imagine that is a difficult task, which would take a human a long time to learn. Luckily, with lots of computer power, we can let a computer play this game!
Now imaging that you are playing this game with three friends. You still take sentences as input, make a drawing, and they use this drawing to create a translation in the language they are learning. This time you get feedback on your drawing from three people, so each thing you draw has to be understandable by all of them. This means you are forced to draw really generic, making drawings that are understandable by everybody. This improves your drawings, and therefore improves your translation in all languages.
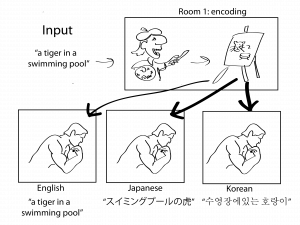
You can also change the roles: three friends create drawings from three different languages and give them to you. Now your task is to use these drawing to create the translation output in one language. Because you have to understand three “drawing styles” you get really good at interpreting. Your friends start to adopt a similar drawing style, as you give feedback on what they do. This improves their drawings, and therefore the translation from all languages.
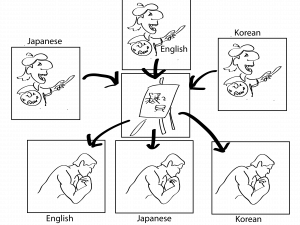
The last version of this game is one where you have multiple people getting input, drawing, and multiple people taking these drawings and translating them. Everybody has to use the same generic drawing style, and the same interpreting style: you never know who gets your image, and you never know whose image you are looking at.
Google now set up this test: what if, during training, the person reading Japanese never gives a drawing to the person translating to Korean, and the person reading Korean never gives a drawing to the person translating to Japanese. If you now give a drawing from a person reading Japanese to somebody translating to Korean, will this yield a good translation? The answer to this question is yes: without training on these language pairs, you can translate from and to these languages.
Actually…
Google does something even more interesting: they only take two persons that do the whole translation process. At the start of the sentence they try to translate they say what language they want to translate to. This means that the sentence “Hello, how are you” becomes “<2es> Hello, how are you?” (to which the answer should be: ¿Hola como estás? ). They don’t even tell the computer what the source language is: the computer will figure this out eventually. Apparently, even if you switch your language halfway during your sentence, the computer can still create the right translation.
Implications
Normally you need a lot of training data from one language to another language to get a good translation model. If you don’t have this parallel data, you can still try to go from one language to a third (more common) language, and translate that to the language you actually wanted. How well something like this works can be seen at the site “translationparty.com”: http://www.translationparty.com/ten-cats-were-eating-their-food-while-five-dogs-were-12843805. With these results, translation from uncommon languages to other uncommon languages would improve without the need for more data.
Hopefully you now understand what Google did, and why this is interesting. If you have any questions, please feel free to contact me.
Facebook Comments (
G+ Comments (add)